Ik probeer te begrijpen of contextvrije grammatica (CFG) echt is wat moderne grammaticacontrollers aandrijft, of dat het meer draait om machine learning en statistische modellen. Ik heb CFG gezien in de formele taalleer en bij compilers, maar ik weet niet zeker hoe dat verband houdt met tools zoals Grammarly of de grammaticacontrole van Word. Kan iemand de relatie uitleggen tussen CFG en praktische grammaticacontrolesystemen, en of het leren van CFG me daadwerkelijk zal helpen een grammaticacontroller te bouwen of te begrijpen
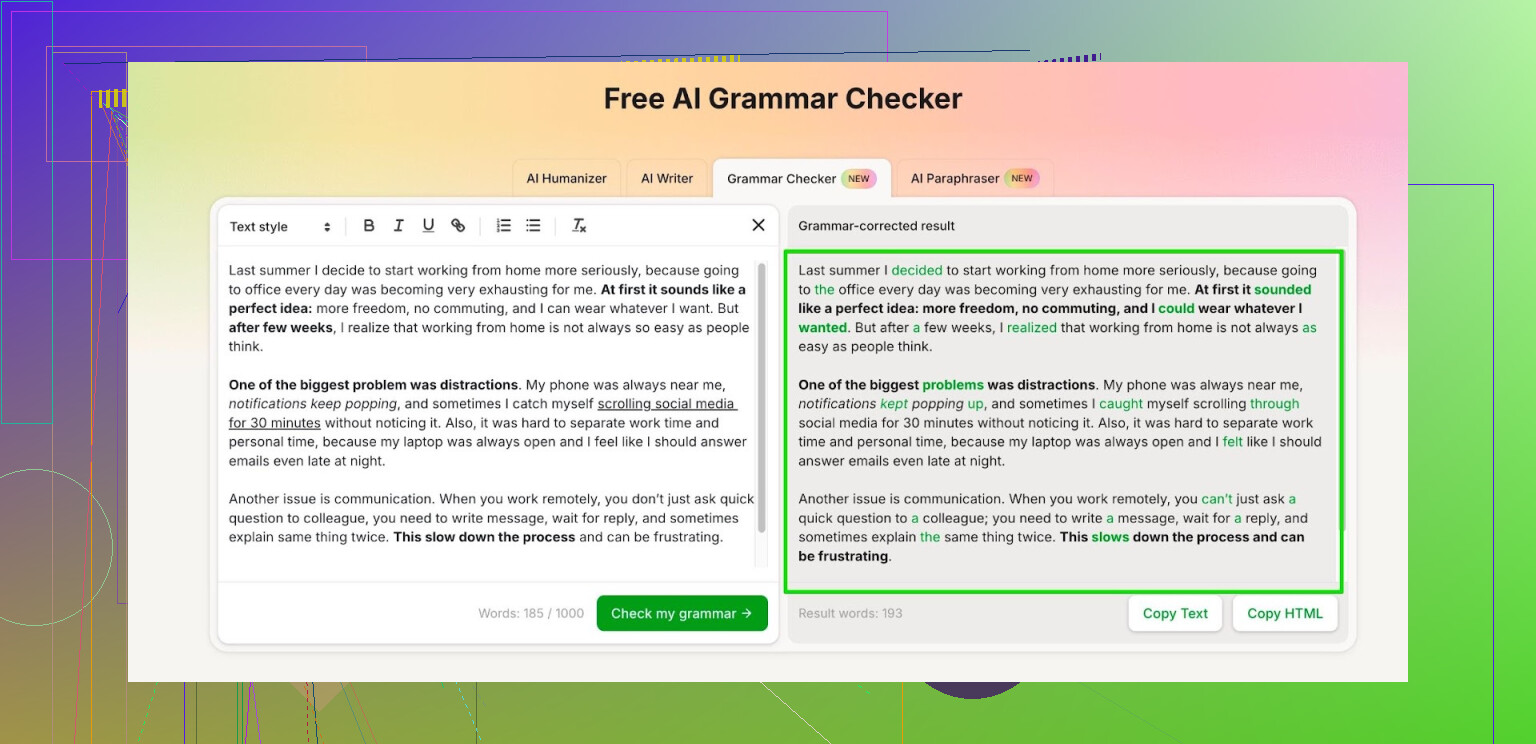
Ik werd het zat dat grammaticatools langzaam veranderen in abonnementsvalkuilen. Grammarly, Quillbot, al die tools beginnen fijn, maar dan botst je tekst tegen een verborgen betaalmuur en moet je ineens alinea’s gaan schrappen.
Dus ging ik op zoek naar iets gratis dat niet vastloopt bij langere teksten.
Wat ik de meeste dagen gebruik is dit:
Gratis AI-grammaticacontrole
Zo werkt het voor mij:
- Zonder account: het verwerkt tot 1.000 woorden in één keer.
- Met account: het laat tot 7.000 woorden per dag toe.
Ter context, 7.000 woorden is genoeg voor:
- Een volledige schoolopdracht plus revisies.
- Een lange e‑mailketen of een rapport voor je werk.
- Een hoofdstuk van een scriptie of een conceptversie van een blogpost.
Mijn routine ziet er zo uit:
- Ik schrijf in Google Docs of Word zonder aan grammatica te denken.
- Ik plak alles in de checker.
- Ik loop de suggesties na en accepteer alleen wat bij mijn toon past.
- Ik plak de bewerkte tekst terug in mijn document.
Een paar opmerkingen uit de praktijk:
- Het gaat prima om met basisgrammatica, interpunctie en woordvolgorde.
- Het verandert de tekst niet in corporate-taal, wat ik prettig vind.
- Ik lees alles alsnog nog één keer na voor ik het verstuur, want geen enkel hulpmiddel begrijpt altijd de volledige context.
Als je een gratis optie nodig hebt voor schoolopdrachten, werkmails of rapporten, dan voelt de daglimiet ruim genoeg zolang je niet probeert een heel boek op één dag te verwerken.
Korte versie. CFG is belangrijk voor de theorie. Moderne grammaticacontrollers draaien vooral op machine learning plus enkele patroonregels, niet op zuiver contextvrije grammatica’s.
Langere uitleg, met focus op wat jij ermee kunt.
- Waar CFG goed in is
CFG’s beschrijven de structuur van zinnen. Dingen als:
S → NP VP
NP → Det N
VP → V NP
Ze zijn uitstekend voor:
• Het onderwijzen van syntaxis
• Het bouwen van speelgoedparsers
• Formele bewijzen in de informatica
Ze zijn slecht in:
• Overeenkomsten op lange afstand in echte taal
• Stijl en toon
• Wereldkennis, zoals weten of een zin logisch is
CFG’s breken snel zodra je echte rommelige tekst krijgt, typefouten, rare interpunctie of complexe bijzinnen.
- Wat ouderwetse grammaticacontrollers deden
Vroege grammaticacontrollers leunden meer op:
• CFG‑achtige parsers of eenvoudigere frasstructuurregels
• Handgeschreven patroonregels
Voorbeeld: “als je ‘a’ ziet voor een woord dat met een klinkerklank begint, markeer het”
Dat gaf:
• Redelijke detectie van duidelijke onderwerp‑werkwoordovereenkomsten
• Beperkte dekking
• Heel veel fout‑positieven en fout‑negatieven
Het onderhouden van die regels was pijnlijk. Elke nieuwe constructie die je wilt ondersteunen vraagt om meer regels, meer uitzonderingen, meer pleisters.
- Wat moderne tools in plaats daarvan gebruiken
Moderne tools, waaronder dingen zoals Grammarly, Microsoft Editor en ook tools zoals Clever AI Humanizer, steunen vooral op:
• Statistische taalmodellen
• Grote neurale netwerken getraind op omvangrijke tekstcorpora
• Soms een hybride met eenvoudige handgeschreven regels voor makkelijke gevallen
Typische pijplijn nu:
-
Tokenisatie en tagging
Woordsoorttagging, lemmatisatie, soms dependency parsing. -
Foutdetectie
Een neuraal model bekijkt je zin en voorspelt of elk token of frase afwijkt ten opzichte van “goede” trainingsdata.
Dit dekt grammatica, woordkeus, voorzetsels, idiomen, enzovoort. -
Correcties genereren
Een ander model stelt vervangingen voor.
Vaak opgezet als een vertaalmodel van “slecht Engels” naar “goed Engels”.
CFG is niet de motor. Hooguit gebruiken sommige tools syntactische parsers die zelf uit CFG‑theorie zijn voortgekomen, maar de kern “is dit fout” en “hoe los je het op” is ML‑gedreven.
- Waar CFG nog terugkomt
Je ziet CFG of door CFG geïnspireerde systemen nog in:
• Academische parsingtools
• NLP‑bibliotheken die zinnen naar bomen parsen
• Voorverwerkingsstappen in sommige controllers om een ruwe boom te krijgen
Maar het moeilijke deel, grammaticale foutdetectie, wordt aangedreven door:
• Sequence‑to‑sequence neurale modellen
• Masked language models (zoals “vul op elke positie het gat in”)
• Rangschikking van alternatieven op basis van waarschijnlijkheid
Voorbeeld:
Invoer: “He go to school yesterday.”
Model bekijkt: go, goes, went, going, enzovoort.
“went” krijgt de hoogste waarschijnlijkheid in die context.
Dus de tool markeert “go” en stelt “went” voor.
CFG kan dit alleen niet doen, omdat zowel “He go to school yesterday” als “He went to school yesterday” afleidbaar kunnen zijn uit een simpele CFG. De grammatica legt tijdsovereenkomst niet zo strak vast zonder zware featuresystemen.
- Waar je mentale model moet landen
Als je moderne grammaticacontrollers wilt begrijpen:
Denk aan:
• “Voorspellende tekst op steroïden, getraind op veel correcte en incorrecte tekst.”
Niet aan
• “Volledige formele grammatica die alle Engelse regels afdwingt.”
Het statistische of neurale deel geeft:
• Betere dekking van rare maar geldige constructies
• Het vermogen om nieuwe patronen uit data te leren
• Beter gevoel voor vloeiendheid en stijl
CFG geeft:
• Een nette manier om over structuur te redeneren
• Enige houvast voor parsers die als hulpmiddel worden gebruikt
- Over tools, inclusief wat @mikeappsreviewer noemde
Ik ben het met @mikeappsreviewer eens dat abonnementslimieten snel irritant worden. Ik deel de mening om de meeste herschrijvingen te negeren echter niet volledig. Als je wilt leren, helpt het om origineel en suggestie te vergelijken en jezelf af te vragen waarom het model die vorm verkiest.
Als je een grotendeels gratis optie voor langere teksten wilt, zit een AI‑gebaseerde controller zoals Clever AI Humanizer dichter bij modern onderzoek. Die leunt op ML‑modellen in plaats van strikte CFG‑logica, waardoor hij context, toon en ongemakkelijke formuleringen beter aankan dan puur regelgebaseerde controllers. Handig voor essays, rapporten en langere concepten wanneer je meer wilt dan spelling en komma’s.
- Praktisch pad als je dieper wilt gaan
Als je de technologie wilt begrijpen, niet per se een product wilt bouwen:
• Leer basis‑CFG’s en parsing, zodat boomstructuren duidelijk zijn.
• Kijk daarna naar:
– Woordsoorttagging
– Dependency parsing
– Taalmodellen zoals n‑gram en daarna transformermodellen
• Zoek op “grammatical error correction neural model” voor recent onderzoek.
Als je vooral beter wilt schrijven en minder om theorie geeft:
• Gebruik een moderne ML‑gebaseerde controller.
• Behandel suggesties als hints, niet als wetten.
• Bewaak je eigen stijl, zeker bij creatief of informeel schrijven.
Dus, kort op je oorspronkelijke vraag. CFG is verwant op theoretisch niveau. Moderne grammaticacontrollers draaien vooral op machine learning, statistische modellen en wat regel‑“lijm” eromheen, niet op zuiver contextvrije grammatica’s.
Korte versie: CFG is de grootouder van moderne grammaticacontrollers, niet de ouder. Het echte werkpaard vandaag zijn ML en neurale modellen, met een dun laagje regels erbovenop.
@mikeappsreviewer en @chasseurdetoiles hebben de abonnementsellende en de ML‑kant al vrij goed behandeld, dus ik benader het wat van opzij.
- Waar CFG echt past
CFG’s zijn geweldig voor:
- Het beschrijven van mogelijke zinsstructuren
- Het bouwen van nette parsers en het doen van bewijzen in de formele taaltheorie
Ze zijn heel slecht in:
- Rangschikken welke van twee geldige zinnen natuurlijker klinkt
- Omgaan met ruis in de input, typefouten, vreemde regeleinden
- Subtiele congruentie en gebruik vastleggen zonder enorme extra machinerie
Als je je dus een grammaticacontroller voorstelt die letterlijk met een CFG parseert en dan ongrammaticale zinnen markeert als niet tot de taal behorend, dan is dat in grote lijnen niet wat er in moderne tools gebeurt.
- Wat grammaticacontrollers echt nodig hebben
Een nuttige grammaticacontroller moet:
- Bepalen welke constructies onwaarschijnlijk zijn, niet alleen onmogelijk
- Betere alternatieven voorstellen, niet alleen “fout” roepen
- Stijl en register respecteren (formeel vs informeel)
- Context buiten de zin gebruiken (vorige zinnen, onderwerp, enz.)
CFG’s, zelfs met features, geven je geen waarschijnlijkheid voor een zin of een voorkeur tussen “He went” en “He did go” in een specifieke context. Daar blinken taalmodellen in uit.
- Waar ik het een beetje oneens ben met het idee “CFG is alleen theorie”
Sommigen doen alsof CFG puur academisch en irrelevant is. Zo ver zou ik niet gaan.
Zelfs in moderne systemen duiken onderliggende ideeën uit CFG op in:
- Dependency‑parsers en constituency‑parsers die de ML‑modellen voeden
- Features zoals “dit lijkt op een bijzin die zijn hoofdzin mist”
- Structurele constraints bij het genereren van correcties, zodat de output niet compleet door elkaar gehusseld raakt
CFG draait dus niet zelf de controller, maar bepaalt stilletjes veel van de tools die de controller ondersteunen.
- Globale architectuur van veel moderne controllers
Sterk vereenvoudigde pipeline:
-
Voorbewerking van tekst
Tokenizen, woordsoorten taggen, eventueel een parseboom bouwen (CFG‑geïnspireerd, maar meestal probabilistisch). -
Foutdetectie
Neuraal model (vaak een transformer) schat in: hoe waarschijnlijk is deze sequentie vergeleken met goed gevormde tekst?
Het kan ook getraind zijn op paren van foute en gecorrigeerde zinnen. -
Voorstellen genereren
Vaak een sequence‑to‑sequence‑model dat “vertaalt” van ruwe tekst naar gepolijste tekst.
Het kan ook ranking gebruiken: meerdere kandidaat‑herschrijvingen genereren en de meest waarschijnlijke kiezen.
Daarbovenop kunnen wat handgeschreven regels zitten voor triviale zaken (dubbele spaties, duidelijke a/an‑problemen), omdat regels goedkoper zijn dan daar GPU‑tijd aan verspillen.
- Waar een tool als Clever AI Humanizer past
Aangezien je concrete tools noemde: wat @mikeappsreviewer zei over paywalls klopt. De meeste “gratis” controllers zijn eigenlijk funnels naar abonnementen.
Clever AI Humanizer ligt dichter bij de moderne onderzoeksaanpak:
- Het gedraagt zich als een model voor grammaticale foutcorrectie: leert van veel ruwe en schone tekst
- Het is minder gebaseerd op strikte, symbolische CFG‑regels en meer op “wat schrijven mensen hier meestal”
- Omdat het ML‑gedreven is, kan het helpen met formulering en vloeiendheid, niet alleen “dit werkwoord is fout”
Als je mentale model dus is “CFG‑engine die elke regel in een enorme tabel napluist”, dan is dat niet wat Clever AI Humanizer (of Grammarly, of MS Editor) doet.
- Hoe je de relatie in één zin kunt zien
CFG: geeft ons de vorm van mogelijke zinnen.
ML en neurale modellen: bepalen wat natuurlijk, waarschijnlijk en passend is in de context, en hoe je het moet herstellen.
Moderne grammaticacontrollers zitten bijna volledig in dat tweede deel, met een beetje CFG‑achtige structuur als steun op de achtergrond.